공부 내용을 정리하고 앞으로의 학습에 이해를 돕기 위해 작성합니다.

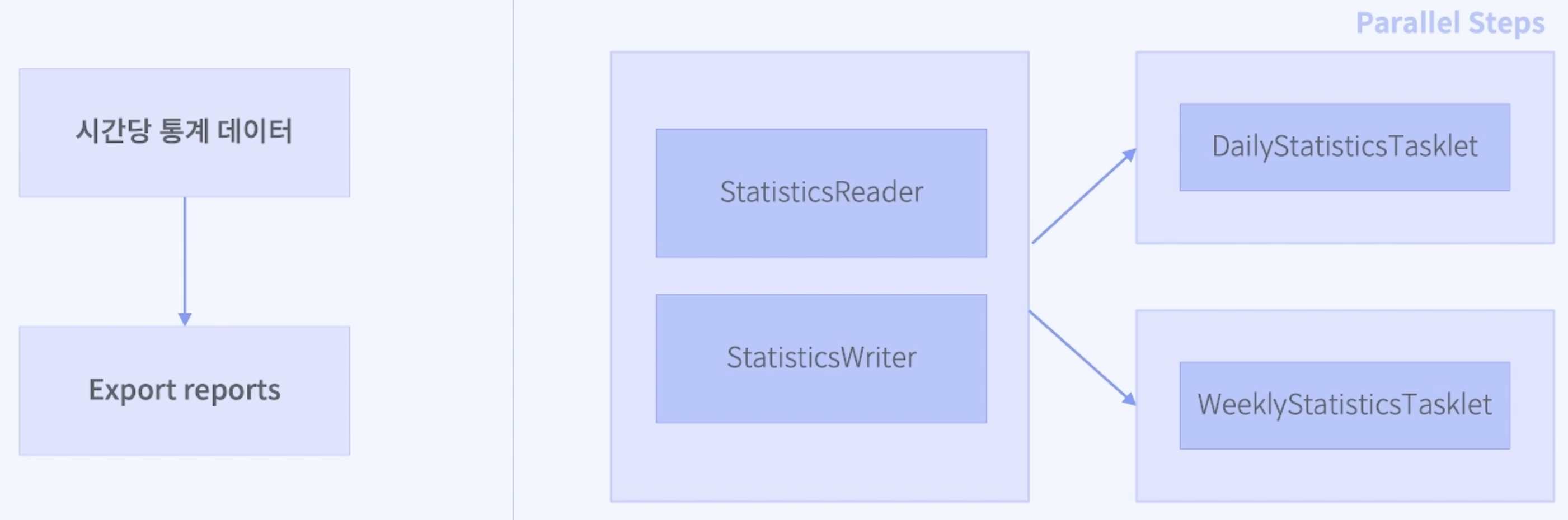
이번 시간에는 배치 기능 구현의 마지막 단계로, 통계 데이터를 생성하는 Job을 패러럴 스텝(Parallel Step)으로 구현한다. 이 Job은 통계 데이터를 생성하고, 이를 기반으로 일별 및 주별 통계를 생성하여 파일로 출력하는 작업을 동시에 처리하는 것이 목표다.
1. 통계 데이터 생성의 필요성
서비스 운영에서 통계 데이터는 매우 중요한 역할을 한다. 특히, 시간 단위로 데이터를 집계하고 분석하는 작업은 서비스 성과를 평가하고, 향후 운영 전략을 수립하는 데 필수적이다. 이번 구현에서는 일별 및 주별 통계 데이터를 생성하고 이를 CSV 파일로 출력하는 작업을 병렬로 처리하여 효율성을 극대화한다.
2. 통계 테이블 추가
먼저 통계 데이터를 저장할 테이블을 생성했다.
CREATE TABLE `statistics`
(
`statistics_seq` int NOT NULL AUTO_INCREMENT COMMENT '통계 순번',
`statistics_at` timestamp NOT NULL COMMENT '통계 일시',
`all_count` int NOT NULL DEFAULT 0 COMMENT '전체 횟수',
`attended_count` int NOT NULL DEFAULT 0 COMMENT '출석 횟수',
`cancelled_count` int NOT NULL DEFAULT 0 COMMENT '취소 횟수',
PRIMARY KEY (`statistics_seq`),
INDEX idx_statistics_at (`statistics_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='통계';- 이 테이블은 각 통계 데이터를 저장하는 데 사용되며, 통계 일시(statistics_at), 전체 횟수(all_count), 출석 횟수(attended_count), 취소 횟수(cancelled_count) 등의 정보를 포함한다.
3. 빈 스코프 개념
이번 구현에서는 빈 스코프(Scope) 개념이 등장한다. 빈 스코프는 스프링 빈의 생성 시점을 제어하는데, JobScope와 StepScope를 통해 Job이나 Step이 실행될 때만 빈이 생성되고 실행이 끝나면 삭제되도록 설정한다. 이는 JobParameter를 실행 시점까지 지연시켜 할당할 수 있게 하고, 동일한 컴포넌트를 병렬로 처리할 때 안전성을 확보할 수 있다.

4. AggregatedStatistics 클래스
AggregatedStatistics 클래스는 통계 데이터를 담는 객체로, statisticsAt(통계 일시), allCount(전체 횟수), attendedCount(출석 횟수), cancelledCount(취소 횟수) 필드를 가지고 있다. 통계 데이터를 병합하는 merge 메서드를 통해 여러 통계 데이터를 하나로 합칠 수 있다.
package com.example.pass.repository.statistics;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import java.time.LocalDateTime;
@Getter
@Setter
@ToString
@AllArgsConstructor
public class AggregatedStatistics {
private LocalDateTime statisticsAt; // 일 단위
private long allCount;
private long attendedCount;
private long cancelledCount;
public void merge(final AggregatedStatistics statistics) {
this.allCount += statistics.getAllCount();
this.attendedCount += statistics.getAttendedCount();
this.cancelledCount += statistics.getCancelledCount();
}
}- 주요 필드
- statisticsAt: 통계가 기록된 날짜와 시간을 나타낸다.
- allCount: 특정 기간 동안의 전체 횟수를 저장한다.
- attendedCount: 특정 기간 동안의 출석 횟수를 저장한다.
- cancelledCount: 특정 기간 동안의 취소 횟수를 저장한다.
- 주요 메서드
- merge(AggregatedStatistics statistics): 이 메서드는 기존 AggregatedStatistics 객체에 새로운 통계 데이터를 병합한다. 예를 들어, 동일한 날짜 또는 주차에 대한 통계 데이터를 합산하는 데 사용된다.
AggregatedStatistics 클래스는 일별 또는 주별로 통계 데이터를 집계하는 데 사용되며, 데이터의 합산이나 병합이 필요한 경우 유용하다.
5. CustomCSVWriter 유틸리티
CustomCSVWriter는 CSV 파일을 생성하는 유틸리티 클래스로, 통계 데이터를 CSV 파일로 저장하는 데 사용된다. 이 클래스는 주어진 데이터 리스트를 받아 지정된 파일명으로 CSV 파일을 생성한다.
package com.example.pass.util;
import com.opencsv.CSVWriter;
import lombok.extern.slf4j.Slf4j;
import java.io.FileWriter;
import java.util.List;
@Slf4j
public class CustomCSVWriter {
public static int write(final String fileName, List<String[]> data) {
int rows = 0;
try (CSVWriter writer = new CSVWriter(new FileWriter(fileName))) {
writer.writeAll(data);
rows = data.size();
} catch (Exception e) {
log.error("CustomCSVWriter - write: CSV 파일 생성 실패, fileName: {}", fileName);
}
return rows;
}
}주요 메서드
- write(String fileName, List<String[]> data): 이 메서드는 주어진 데이터를 CSV 파일로 저장한다. fileName은 생성할 파일의 이름을 지정하며, data는 CSV 파일에 기록할 데이터 리스트를 의미한다.
CustomCSVWriter는 통계 데이터를 파일로 출력하는 작업을 간단하고 효율적으로 수행할 수 있게 해 주며, 로그를 통해 파일 생성 실패 시의 상황을 기록할 수 있다.
6. MakeDailyStatisticsTasklet과 MakeWeeklyStatisticsTasklet
이 두 개의 Tasklet은 각각 일별 및 주별 통계 데이터를 생성하고 이를 CSV 파일로 저장하는 작업을 수행한다.
package com.example.pass.job.statistics;
import com.example.pass.repository.statistics.AggregatedStatistics;
import com.example.pass.repository.statistics.StatisticsRepository;
import com.example.pass.util.CustomCSVWriter;
import com.example.pass.util.LocalDateTimeUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@Component
@StepScope
public class MakeDailyStatisticsTasklet implements Tasklet {
@Value("#{jobParameters[from]}")
private String fromString;
@Value("#{jobParameters[to]}")
private String toString;
private final StatisticsRepository statisticsRepository;
public MakeDailyStatisticsTasklet(StatisticsRepository statisticsRepository) {
this.statisticsRepository = statisticsRepository;
}
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
final LocalDateTime from = LocalDateTimeUtils.parse(fromString);
final LocalDateTime to = LocalDateTimeUtils.parse(toString);
final List<AggregatedStatistics> statisticsList = statisticsRepository.findByStatisticsAtBetweenAndGroupBy(from, to);
List<String[]> data = new ArrayList<>();
data.add(new String[]{"statisticsAt", "allCount", "attendedCount", "cancelledCount"});
for (AggregatedStatistics statistics : statisticsList) {
data.add(new String[]{
LocalDateTimeUtils.format(statistics.getStatisticsAt()),
String.valueOf(statistics.getAllCount()),
String.valueOf(statistics.getAttendedCount()),
String.valueOf(statistics.getCancelledCount())
});
}
CustomCSVWriter.write("daily_statistics_" + LocalDateTimeUtils.format(from, LocalDateTimeUtils.YYYY_MM_DD) + ".csv", data);
return RepeatStatus.FINISHED;
}
}- 주요 필드
- fromString, toString: 배치 작업에서 전달받은 시작일(from)과 종료일(to)을 나타내는 문자열이다.
- statisticsRepository: 통계 데이터를 조회하고 관리하는 리포지토리이다.
- 주요 메서드
- execute(StepContribution contribution, ChunkContext chunkContext): 이 메서드는 지정된 기간 동안의 통계 데이터를 조회하고, 이를 CSV 파일로 저장하는 작업을 수행한다. 일별 통계 데이터를 조회하여 CustomCSVWriter를 사용해 파일로 출력한다.
이 Tasklet은 지정된 기간 동안의 일별 통계를 수집하고, 이를 CSV 파일로 출력하여 저장하는 역할을 수행한다.
MakeWeeklyStatisticsTasklet은 주별 통계 데이터를 생성하고 이를 CSV 파일로 저장하는 역할을 하는 Tasklet이다.
package com.example.pass.job.statistics;
import com.example.pass.repository.statistics.AggregatedStatistics;
import com.example.pass.repository.statistics.StatisticsRepository;
import com.example.pass.util.CustomCSVWriter;
import com.example.pass.util.LocalDateTimeUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
@Slf4j
@Component
@StepScope
public class MakeWeeklyStatisticsTasklet implements Tasklet {
@Value("#{jobParameters[from]}")
private String fromString;
@Value("#{jobParameters[to]}")
private String toString;
private final StatisticsRepository statisticsRepository;
public MakeWeeklyStatisticsTasklet(StatisticsRepository statisticsRepository) {
this.statisticsRepository = statisticsRepository;
}
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
final LocalDateTime from = LocalDateTimeUtils.parse(fromString);
final LocalDateTime to = LocalDateTimeUtils.parse(toString);
final List<AggregatedStatistics> statisticsList = statisticsRepository.findByStatisticsAtBetweenAndGroupBy(from, to);
Map<Integer, AggregatedStatistics> weeklyStatisticsEntityMap = new LinkedHashMap<>();
for (AggregatedStatistics statistics : statisticsList) {
int week = LocalDateTimeUtils.getWeekOfYear(statistics.getStatisticsAt());
AggregatedStatistics savedStatisticsEntity = weeklyStatisticsEntityMap.get(week);
if (savedStatisticsEntity == null) {
weeklyStatisticsEntityMap.put(week, statistics);
} else {
savedStatisticsEntity.merge(statistics);
}
}
List<String[]> data = new ArrayList<>();
data.add(new String[]{"week", "allCount", "attendedCount", "cancelledCount"});
weeklyStatisticsEntityMap.forEach((week, statistics) -> {
data.add(new String[]{
"Week " + week,
String.valueOf(statistics.getAllCount()),
String.valueOf(statistics.getAttendedCount()),
String.valueOf(statistics.getCancelledCount())
});
});
CustomCSVWriter.write("weekly_statistics_" + LocalDateTimeUtils.format(from, LocalDateTimeUtils.YYYY_MM_DD) + ".csv", data);
return RepeatStatus.FINISHED;
}
}- 주요 필드
- fromString, toString: 배치 작업에서 전달받은 시작일(from)과 종료일(to)을 나타내는 문자열이다.
- statisticsRepository: 통계 데이터를 조회하고 관리하는 리포지토리이다.
- 주요 메서드
- execute(StepContribution contribution, ChunkContext chunkContext): 이 메서드는 지정된 기간 동안의 통계 데이터를 주차별로 그룹화하여 CSV 파일로 저장하는 작업을 수행한다. 주차별 통계 데이터를 집계하여 CustomCSVWriter를 사용해 파일로 출력한다.
이 Tasklet은 지정된 기간 동안의 주별 통계를 수집하고, 이를 주차별로 그룹화한 후 CSV 파일로 출력하여 저장하는 역할을 수행한다.
7. MakeStatisticsJobConfig
MakeStatisticsJobConfig 클래스는 통계 데이터를 생성하고, 이를 일별 및 주별로 병렬 처리하여 CSV 파일로 저장하는 배치 작업을 설정하는 구성 클래스이다. 이 클래스는 스프링 배치에서 Job, Step, Tasklet 등을 설정하여 복잡한 배치 작업을 효율적으로 처리할 수 있도록 한다.
package com.example.pass.job.statistics;
import com.example.pass.repository.booking.BookingEntity;
import com.example.pass.repository.statistics.StatisticsEntity;
import com.example.pass.repository.statistics.StatisticsRepository;
import com.example.pass.util.LocalDateTimeUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.builder.FlowBuilder;
import org.springframework.batch.core.job.flow.Flow;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaCursorItemReader;
import org.springframework.batch.item.database.builder.JpaCursorItemReaderBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.SimpleAsyncTaskExecutor;
import javax.persistence.EntityManagerFactory;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
@Slf4j
@Configuration
public class MakeStatisticsJobConfig {
private final int CHUNK_SIZE = 10;
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory entityManagerFactory;
private final StatisticsRepository statisticsRepository;
private final MakeDailyStatisticsTasklet makeDailyStatisticsTasklet;
private final MakeWeeklyStatisticsTasklet makeWeeklyStatisticsTasklet;
public MakeStatisticsJobConfig(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory, EntityManagerFactory entityManagerFactory, StatisticsRepository statisticsRepository, MakeDailyStatisticsTasklet makeDailyStatisticsTasklet, MakeWeeklyStatisticsTasklet makeWeeklyStatisticsTasklet) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.entityManagerFactory = entityManagerFactory;
this.statisticsRepository = statisticsRepository;
this.makeDailyStatisticsTasklet = makeDailyStatisticsTasklet;
this.makeWeeklyStatisticsTasklet = makeWeeklyStatisticsTasklet;
}
@Bean
public Job makeStatisticsJob() {
Flow addStatisticsFlow = new FlowBuilder<Flow>("addStatisticsFlow")
.start(addStatisticsStep())
.build();
Flow makeDailyStatisticsFlow = new FlowBuilder<Flow>("makeDailyStatisticsFlow")
.start(makeDailyStatisticsStep())
.build();
Flow makeWeeklyStatisticsFlow = new FlowBuilder<Flow>("makeWeeklyStatisticsFlow")
.start(makeWeeklyStatisticsStep())
.build();
Flow parallelMakeStatisticsFlow = new FlowBuilder<Flow>("parallelMakeStatisticsFlow")
.split(new SimpleAsyncTaskExecutor())
.add(makeDailyStatisticsFlow, makeWeeklyStatisticsFlow)
.build();
return this.jobBuilderFactory.get("makeStatisticsJob")
.start(addStatisticsFlow)
.next(parallelMakeStatisticsFlow)
.build()
.build();
}
@Bean
public Step addStatisticsStep() {
return this.stepBuilderFactory.get("addStatisticsStep")
.<BookingEntity, BookingEntity>chunk(CHUNK_SIZE)
.reader(addStatisticsItemReader(null, null))
.writer(addStatisticsItemWriter())
.build();
}
@Bean
@StepScope
public JpaCursorItemReader<BookingEntity> addStatisticsItemReader(@Value("#{jobParameters[from]}") String fromString, @Value("#{jobParameters[to]}") String toString) {
final LocalDateTime from = LocalDateTimeUtils.parse(fromString);
final LocalDateTime to = LocalDateTimeUtils.parse(toString);
return new JpaCursorItemReaderBuilder<BookingEntity>()
.name("usePassesItemReader")
.entityManagerFactory(entityManagerFactory)
// JobParameter를 받아 종료 일시(endedAt) 기준으로 통계 대상 예약(Booking)을 조회합니다.
.queryString("select b from BookingEntity b where b.endedAt between :from and :to")
.parameterValues(Map.of("from", from, "to", to))
.build();
}
@Bean
public ItemWriter<BookingEntity> addStatisticsItemWriter() {
return bookingEntities -> {
Map<LocalDateTime, StatisticsEntity> statisticsEntityMap = new LinkedHashMap<>();
for (BookingEntity bookingEntity : bookingEntities) {
final LocalDateTime statisticsAt = bookingEntity.getStatisticsAt();
StatisticsEntity statisticsEntity = statisticsEntityMap.get(statisticsAt);
if (statisticsEntity == null) {
statisticsEntityMap.put(statisticsAt, StatisticsEntity.create(bookingEntity));
} else {
statisticsEntity.add(bookingEntity);
}
}
final List<StatisticsEntity> statisticsEntities = new ArrayList<>(statisticsEntityMap.values());
statisticsRepository.saveAll(statisticsEntities);
log.info("### addStatisticsStep 종료");
};
}
@Bean
public Step makeDailyStatisticsStep() {
return this.stepBuilderFactory.get("makeDailyStatisticsStep")
.tasklet(makeDailyStatisticsTasklet)
.build();
}
@Bean
public Step makeWeeklyStatisticsStep() {
return this.stepBuilderFactory.get("makeWeeklyStatisticsStep")
.tasklet(makeWeeklyStatisticsTasklet)
.build();
}
}주요 역할
- Job 구성: 통계 데이터를 생성하고 이를 병렬로 처리하는 작업 흐름을 정의한다. 이 작업은 여러 개의 Step으로 구성되며, 각각의 Step은 통계 데이터를 집계하거나 CSV 파일로 출력하는 역할을 한다.
- Step 정의: 각 Step은 특정 작업을 수행하며, 여기서는 통계 데이터를 생성하는 Step과 생성된 데이터를 일별 및 주별로 파일에 출력하는 Tasklet이 포함된다.
세부 설명
- 필드 정의
- jobBuilderFactory, stepBuilderFactory: 스프링 배치에서 Job과 Step을 생성하는 데 사용되는 팩토리 객체들이다.
- entityManagerFactory: JPA를 통해 데이터베이스와 상호작용하기 위한 엔티티 매니저 팩토리다. 통계 데이터를 읽어오고 데이터베이스에 저장하는 데 사용된다.
- statisticsRepository: 통계 데이터를 관리하는 리포지토리 인터페이스로, 통계 데이터를 조회하고 집계된 결과를 반환하는 메서드를 제공한다.
- makeDailyStatisticsTasklet, makeWeeklyStatisticsTasklet: 각각 일별 및 주별 통계 데이터를 생성하고, 이를 CSV 파일로 저장하는 Tasklet이다.
- Job 정의 (makeStatisticsJob)
- makeStatisticsJob 메서드는 전체 배치 작업을 정의한다. 이 Job은 통계 데이터를 생성하고, 이를 병렬로 처리하여 일별 및 주별 CSV 파일로 출력하는 여러 Step으로 구성된다.
- addStatisticsFlow: 예약 데이터를 기반으로 통계 데이터를 생성하는 작업을 정의한 Flow다. 예약 데이터를 읽어와 통계 데이터로 변환하고, 이를 데이터베이스에 저장하는 역할을 수행한다.
- makeDailyStatisticsFlow: 일별 통계 데이터를 생성하고, 이를 CSV 파일로 출력하는 Tasklet을 실행하는 Flow다.
- makeWeeklyStatisticsFlow: 주별 통계 데이터를 생성하고, 이를 CSV 파일로 출력하는 Tasklet을 실행하는 Flow다.
- parallelMakeStatisticsFlow: SimpleAsyncTaskExecutor를 사용해 makeDailyStatisticsFlow와 makeWeeklyStatisticsFlow를 병렬로 실행하도록 설정된 Flow다. 병렬 처리를 통해 전체 작업의 효율성을 극대화할 수 있다.
- Step 정의
- addStatisticsStep: 예약 데이터를 읽고 통계 데이터를 생성하는 Step이다. JpaCursorItemReader를 사용해 BookingEntity 데이터를 읽어오고, ItemWriter를 통해 이를 통계 데이터로 변환하여 데이터베이스에 저장한다.
- makeDailyStatisticsStep: 일별 통계 데이터를 생성하고, 이를 CSV 파일로 출력하는 Tasklet을 실행하는 Step이다.
- makeWeeklyStatisticsStep: 주별 통계 데이터를 생성하고, 이를 CSV 파일로 출력하는 Tasklet을 실행하는 Step이다.
- ItemReader 정의 (addStatisticsItemReader)
- addStatisticsItemReader는 JpaCursorItemReader를 사용하여 BookingEntity 데이터를 데이터베이스에서 읽어오는 역할을 한다. 이 리더는 fromString과 toString으로 전달된 JobParameter를 사용해 특정 기간 동안 종료된 예약 데이터를 조회한다. 쿼리에서는 endedAt 필드가 주어진 기간 내에 있는 예약 데이터만을 조회하도록 설정된다.
- ItemWriter 정의 (addStatisticsItemWriter)
- addStatisticsItemWriter는 읽어온 BookingEntity 데이터를 StatisticsEntity로 변환하여 통계 데이터를 생성하고, 이를 데이터베이스에 저장하는 역할을 한다. 이 Writer는 데이터를 날짜별로 그룹화하여 저장하며, 통계 데이터를 효율적으로 관리할 수 있도록 한다.
8. StatisticsEntity
StatisticsEntity는 통계 데이터를 저장하는 엔티티 클래스로, 통계 테이블의 각 행을 나타낸다. 이 클래스는 통계 데이터를 관리하고, 데이터베이스에 저장하는 역할을 한다.
package com.example.pass.repository.statistics;
import com.example.pass.repository.booking.BookingEntity;
import com.example.pass.repository.booking.BookingStatus;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import javax.persistence.*;
import java.time.LocalDateTime;
@Getter
@Setter
@ToString
@Entity
@Table(name = "statistics")
public class StatisticsEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 기본 키 생성을 DB에 위임합니다. (AUTO_INCREMENT)
private Integer statisticsSeq;
private LocalDateTime statisticsAt; // 일 단위
private int allCount;
private int attendedCount;
private int cancelledCount;
public static StatisticsEntity create(final BookingEntity bookingEntity) {
StatisticsEntity statisticsEntity = new StatisticsEntity();
statisticsEntity.setStatisticsAt(bookingEntity.getStatisticsAt());
statisticsEntity.setAllCount(1);
if (bookingEntity.isAttended()) {
statisticsEntity.setAttendedCount(1);
}
if (BookingStatus.CANCELLED.equals(bookingEntity.getStatus())) {
statisticsEntity.setCancelledCount(1);
}
return statisticsEntity;
}
public void add(final BookingEntity bookingEntity) {
this.allCount++;
if (bookingEntity.isAttended()) {
this.attendedCount++;
}
if (BookingStatus.CANCELLED.equals(bookingEntity.getStatus())) {
this.cancelledCount++;
}
}
}- 주요 필드
- statisticsSeq: 통계 순번으로, 기본 키 역할을 한다. 이 값은 자동 증가(AUTO_INCREMENT)로 설정된다.
- statisticsAt: 통계 일시로, 통계가 기록된 날짜와 시간을 나타낸다.
- allCount: 전체 횟수를 나타낸다.
- attendedCount: 출석 횟수를 나타낸다.
- cancelledCount: 취소 횟수를 나타낸다.
- 주요 메서드
- create(BookingEntity bookingEntity): 주어진 BookingEntity를 기반으로 새로운 StatisticsEntity를 생성한다. 이 메서드는 새로 생성된 통계 데이터를 초기화하는 데 사용된다.
- add(BookingEntity bookingEntity): 기존 통계 데이터에 새로운 데이터를 추가한다. 예를 들어, 동일한 날짜의 예약 데이터를 집계할 때 사용된다.
이 클래스는 통계 데이터를 효과적으로 관리하고 업데이트하기 위한 필수적인 역할을 하며, BookingEntity에서 가져온 데이터를 통해 통계 정보를 생성하고, 필요에 따라 데이터를 병합한다.
9. StatisticsRepository
StatisticsRepository는 StatisticsEntity를 데이터베이스에 저장하고 조회하는 역할을 하는 Spring Data JPA 리포지토리 인터페이스다. 이 리포지토리는 통계 데이터를 효율적으로 조회하고 집계된 통계를 반환하는 메서드를 제공한다.
package com.example.pass.repository.statistics;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.time.LocalDateTime;
import java.util.List;
public interface StatisticsRepository extends JpaRepository<StatisticsEntity, Integer> {
@Query(value = "SELECT new com.fastcampus.pass.repository.statistics.AggregatedStatistics(s.statisticsAt, SUM(s.allCount), SUM(s.attendedCount), SUM(s.cancelledCount)) " +
" FROM StatisticsEntity s " +
" WHERE s.statisticsAt BETWEEN :from AND :to " +
" GROUP BY s.statisticsAt")
List<AggregatedStatistics> findByStatisticsAtBetweenAndGroupBy(@Param("from") LocalDateTime from, @Param("to") LocalDateTime to);
}주요 메서드
- findByStatisticsAtBetweenAndGroupBy(LocalDateTime from, LocalDateTime to): 이 메서드는 주어진 기간(from에서 to 사이)에 해당하는 통계 데이터를 그룹화하여 집계된 결과를 반환한다. 반환된 결과는 AggregatedStatistics 객체로 표현되며, 이는 통계 데이터를 집계하여 관리하는 데 사용된다.
MakeStatisticsJobConfig 클래스는 통계 데이터를 생성하고, 이를 일별 및 주별로 병렬 처리하여 CSV 파일로 출력하는 배치 작업을 설정하는 데 중요한 역할을 한다. 이 클래스는 각 Step을 정의하고, 데이터의 읽기, 처리, 쓰기 작업을 관리함으로써 대량의 데이터를 효율적으로 처리할 수 있도록 설계되었다. 이를 통해 일일 및 주간 보고서를 신속하게 생성하고, 서비스 운영에 필요한 중요한 통계 데이터를 적시에 제공할 수 있다.
이번 통계 데이터 생성 작업을 통해 일별 및 주별 통계를 효과적으로 집계하고, 병렬 처리를 활용해 작업 시간을 단축할 수 있었다. 이로 인해 대량의 데이터를 효율적으로 관리하고, 서비스 운영에 필요한 통계 데이터를 신속하게 제공할 수 있다. 이러한 배치 작업은 데이터 분석과 보고서 생성에 있어 중요한 역할을 한다.
'BackEnd > Project' 카테고리의 다른 글
| [PT Manager] Ch03. Web 이용권 조회 페이지 (1) | 2024.08.28 |
|---|---|
| [PT Manager] Ch03. Web 프로젝트 생성 및 git 설정 (0) | 2024.08.28 |
| [PT Manager] Ch03. Batch 수업 종료 후 이용권 차감 (0) | 2024.08.28 |
| [PT Manager] Ch03. Batch 예약된 수업 전 알람(외부 채널 알람 연동) (0) | 2024.08.28 |
| [PT Manager] Ch03. Batch 이용권 일괄 지급 (0) | 2024.08.27 |



