데이터 인코딩은 효율적인 데이터 표현과 전송을 가능하게 한다. Base62와 Base64는 각각의 특성을 바탕으로 다양한 상황에서 활용되며, 특히 Base62는 URL 안전성과 데이터 효율성에서 주목받는다.
Base62는 영문 대소문자와 숫자만을 사용해 URL에서 추가적인 인코딩 없이 안전하게 사용할 수 있다. 반면 Base64는 특수 문자를 포함해 바이너리 데이터를 다루는 데 효율적이지만, URL에서는 추가 인코딩이 필요할 수 있다.
이 분석에서는 두 방식의 특성을 비교하고, Base62의 장점에 중점을 두어 각 방식의 장단점을 파악하고자 한다.
테스트 코드를 통한 비교
Spock 프레임워크를 사용한 Groovy 테스트 코드를 작성하여 Base62와 Base64의 차이를 실험적으로 비교해 보았다. 테스트에는 패딩이 필요한 문자열과 패딩이 필요 없는 문자열 두 가지 유형을 사용하였다.
import io.seruco.encoding.base62.Base62
import org.apache.commons.codec.binary.Base64
import spock.lang.Specification
import java.security.SecureRandom
import java.util.concurrent.TimeUnit
class EncodingBenchmarkTest extends Specification {
def base62 = Base62.createInstance()
def "Base64와 Base62의 URL 안전성 비교 테스트"() {
given: "테스트할 문자열 준비"
def testStrings = [
"This is a test string that will produce padding", // 패딩이 필요한 문자열
"This is another test string without padding" // 패딩이 필요 없는 문자열
]
def base62 = Base62.createInstance()
testStrings.each { testString ->
println "\n테스트 문자열: $testString"
when: "Base64 인코딩 수행"
def base64Encoded = Base64.encodeBase64String(testString.getBytes("UTF-8"))
def urlEncodedBase64 = URLEncoder.encode(base64Encoded, "UTF-8")
def decodedFromUrlEncodedBase64 = new String(Base64.decodeBase64(URLDecoder.decode(urlEncodedBase64, "UTF-8")), "UTF-8")
then: "Base64 결과 확인"
println "Base64 인코딩 결과: $base64Encoded"
println "URL 인코딩된 Base64: $urlEncodedBase64"
println "URL 디코딩 후 Base64 디코딩 결과: $decodedFromUrlEncodedBase64"
base64Encoded.count('=') <= 2 // 패딩은 0, 1, 또는 2개 가능
urlEncodedBase64.count("%3D") == base64Encoded.count('=')
decodedFromUrlEncodedBase64 == testString
when: "Base62 인코딩 수행"
def base62Encoded = new String(base62.encode(testString.getBytes("UTF-8")))
def urlEncodedBase62 = URLEncoder.encode(base62Encoded, "UTF-8")
def decodedFromUrlEncodedBase62 = new String(base62.decode(URLDecoder.decode(urlEncodedBase62, "UTF-8").getBytes()), "UTF-8")
then: "Base62 결과 확인"
println "Base62 인코딩 결과: $base62Encoded"
println "URL 인코딩된 Base62: $urlEncodedBase62"
println "URL 디코딩 후 Base62 디코딩 결과: $decodedFromUrlEncodedBase62"
!base62Encoded.contains('=')
!base62Encoded.contains('+')
!base62Encoded.contains('/')
urlEncodedBase62 == base62Encoded // URL 인코딩이 필요 없음
decodedFromUrlEncodedBase62 == testString
when: "Base64에서 패딩 제거"
def base64EncodedNoPadding = base64Encoded.replaceAll("=+\$", "")
def decodedNoPaddingBase64 = new String(Base64.decodeBase64(base64EncodedNoPadding), "UTF-8")
then: "Base64 패딩 제거 결과 확인"
println "패딩이 제거된 Base64: $base64EncodedNoPadding"
println "패딩 제거 후 Base64 디코딩 결과: $decodedNoPaddingBase64"
decodedNoPaddingBase64 == testString // 패딩이 없어도 디코딩은 가능할 수 있음
when: "Base62에서 문자 제거 시도"
def base62EncodedModified = base62Encoded.substring(0, base62Encoded.length() - 1)
then: "Base62 문자 제거 시 예외 발생 또는 디코딩 실패 확인"
try {
def decodedModifiedBase62 = new String(base62.decode(base62EncodedModified.getBytes()), "UTF-8")
assert decodedModifiedBase62 != testString, "Base62 디코딩 결과가 원본과 달라야 함"
} catch (Exception e) {
println "Base62 문자 제거 시 예외 발생: ${e.message}"
}
}
}
def "실제 주소 인코딩/디코딩 테스트"() {
given:
def addresses = [
"서울특별시 강남구 테헤란로 152",
"123 Main St, New York, NY 10001",
"부산광역시 해운대구 우동 센텀2로 25"
]
when:
addresses.each { address ->
def encoded = new String(base62.encode(address.getBytes("UTF-8")))
def decoded = new String(base62.decode(encoded.getBytes("UTF-8")), "UTF-8")
println "Original: $address"
println "Encoded: $encoded"
println "Decoded: $decoded"
println "---"
assert address == decoded
}
then:
true
}
def "특수 문자가 포함된 주소 테스트"() {
given:
def specialAddress = "123 Main St. #456, (City), [State] 12345 & More! 서울특별시"
when:
def base62Encoded = new String(base62.encode(specialAddress.getBytes("UTF-8")))
def base64Encoded = Base64.encodeBase64URLSafeString(specialAddress.getBytes("UTF-8"))
def urlEncoded = URLEncoder.encode(specialAddress, "UTF-8")
then:
!base62Encoded.contains('+')
!base62Encoded.contains('/')
!base62Encoded.contains('=')
println "Original: $specialAddress"
println "Base62 encoded: $base62Encoded"
println "Base64 URL Safe encoded: $base64Encoded"
println "URL encoded: $urlEncoded"
assert specialAddress == new String(base62.decode(base62Encoded.getBytes("UTF-8")), "UTF-8")
assert specialAddress == new String(Base64.decodeBase64(base64Encoded), "UTF-8")
assert specialAddress == URLDecoder.decode(urlEncoded, "UTF-8")
}
def "Base62와 Base64 인코딩 성능 및 결과 길이 비교"() {
given:
def inputSizes = [10, 100, 1000, 10000]
def base62 = Base62.createInstance()
when:
inputSizes.each { size ->
println "입력 크기: $size 바이트"
def input = generateRandomString(size)
def iterations = size <= 1000 ? 1000 : 10
def (base62Time, base62Length) = benchmark("Base62", iterations) {
new String(base62.encode(input.getBytes()))
}
def (base64Time, base64Length) = benchmark("Base64", iterations) {
Base64.encodeBase64String(input.getBytes())
}
println "Base62: ${base62Time}ms, 길이: ${base62Length}"
println "Base64: ${base64Time}ms, 길이: ${base64Length}"
println "---"
}
then:
true
}
private String generateRandomString(int length) {
def chars = ('A'..'Z') + ('a'..'z') + ('0'..'9')
def random = new SecureRandom()
random.with {
(1..length).collect { chars[nextInt(chars.size())] }.join()
}
}
private def benchmark(String name, int iterations, Closure task) {
def start = System.nanoTime()
def result = null
iterations.times {
result = task()
}
def end = System.nanoTime()
def time = TimeUnit.NANOSECONDS.toMillis(end - start)
def length = result.length()
[time, length]
}
}
Base62와 Base64의 URL 안전성 비교

1. URL 안전성
- Base64: 인코딩 결과에 '=' 패딩 문자가 포함된다. URL 인코딩 시 '=' 문자가 '%3D'로 변환된다. URL 디코딩 후 원본 문자열로 정확히 복원된다.
- Base62: 인코딩 결과에 URL 안전하지 않은 문자가 포함되지 않으며, 추가적인 URL 인코딩이 필요 없다. URL 디코딩 후 원본 문자열로 정확히 복원된다.
2. 패딩 처리
- Base64: 패딩 문자를 포함하며, 패딩을 제거해도 디코딩이 정상적으로 작동한다. 패딩이 제거된 인코딩 결과도 원본 문자열로 정확히 복원된다.
- Base62: 패딩 문자를 사용하지 않으며, 모든 문자가 의미를 가지므로 추가적인 패딩 제거 처리가 필요 없다.
3. 다국어 지원
- 두 방식 모두 한글, 영어, 숫자, 특수문자를 포함한 문자열을 정확히 인코딩/디코딩한다.
4. 인코딩 길이
- Base64: 인코딩 결과가 상대적으로 짧다.
- Base62: 인코딩 결과가 Base64보다 약간 더 길다.
5. 특수 문자 처리
- Base64: '+', '/', '=' 등의 특수 문자를 포함할 수 있으며, 이는 URL에서 문제가 될 수 있다.
- Base62: 이러한 특수 문자를 포함하지 않으며, URL에서 안전하게 사용할 수 있다.
실제 주소 인코딩/디코딩 테스트 (Base62와 Base64 비교)
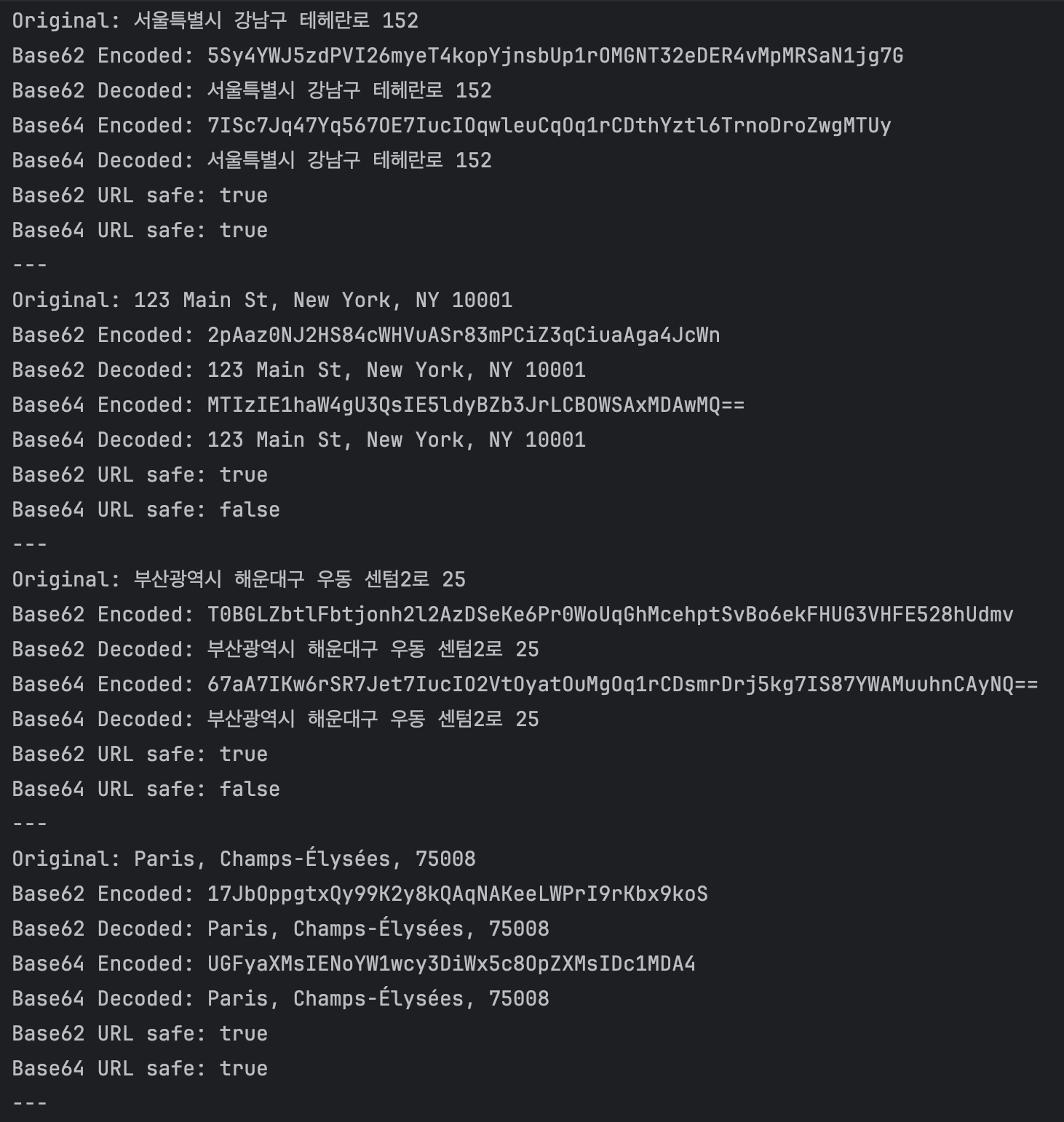
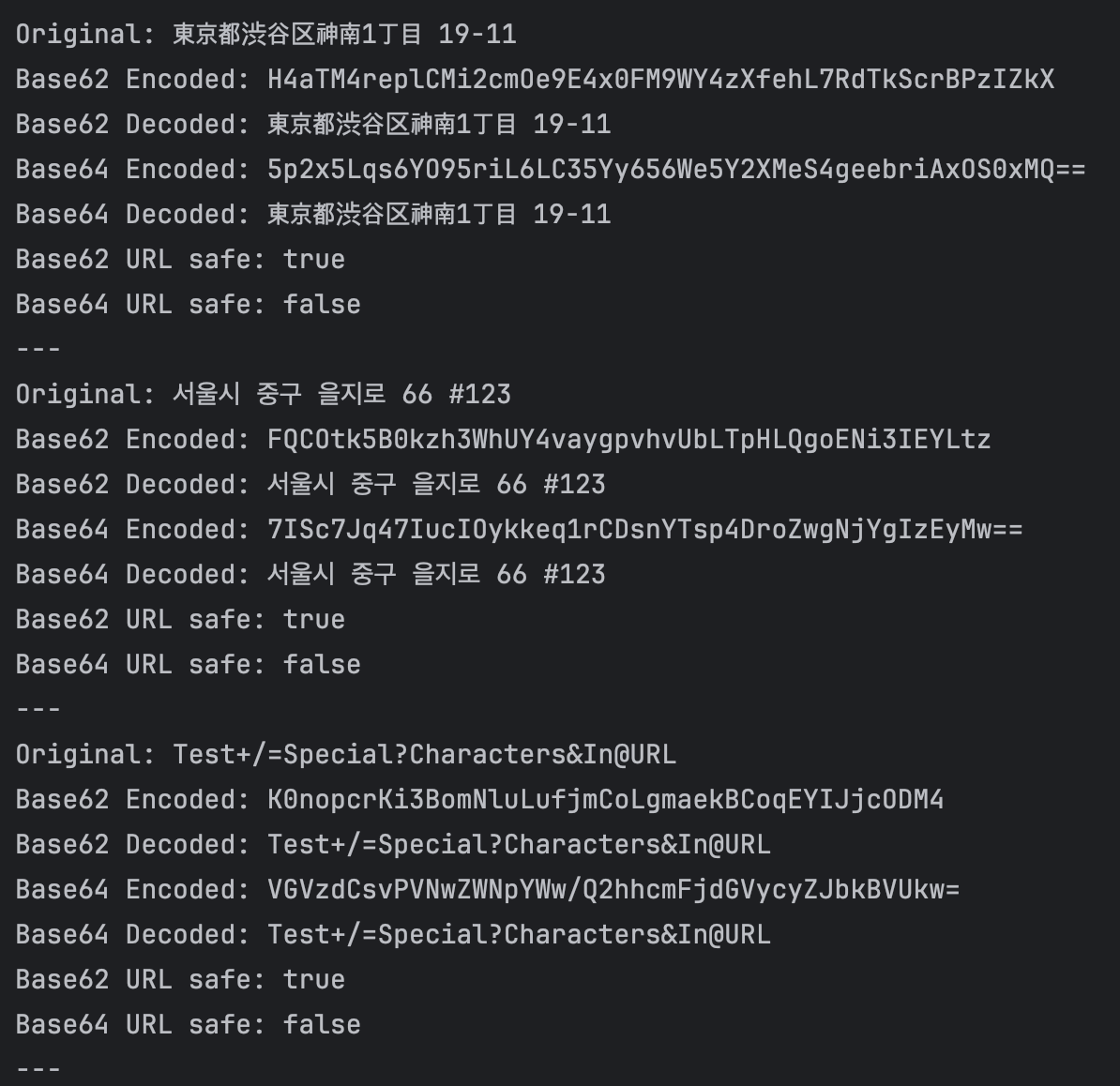
1. URL 안전성
- Base62는 모든 테스트 케이스에서 URL 안전한 결과를 제공했다.
- Base64는 7개 중 5개의 케이스에서 URL 안전하지 않은 문자('+', '/', '=')를 포함했다.
2. 특수 문자 처리
- Base62는 '+', '/', '=' 등의 특수 문자를 포함한 입력도 안전하게 인코딩했다.
- Base64는 이러한 특수 문자를 그대로 인코딩 결과에 포함시켰다.
3. 다국어 지원
- 두 방식 모두 한글, 영어, 일본어 등 다양한 언어를 정확히 인코딩/디코딩했다.
4. 패딩
- Base62는 패딩 문자를 사용하지 않았다.
- Base64는 많은 경우에 '=' 패딩 문자를 사용했다.
5. 인코딩 길이
- 대체로 Base62 인코딩 결과가 Base64보다 조금 더 길었다.
Base62와 Base64 인코딩 성능 및 결과 길이 비교
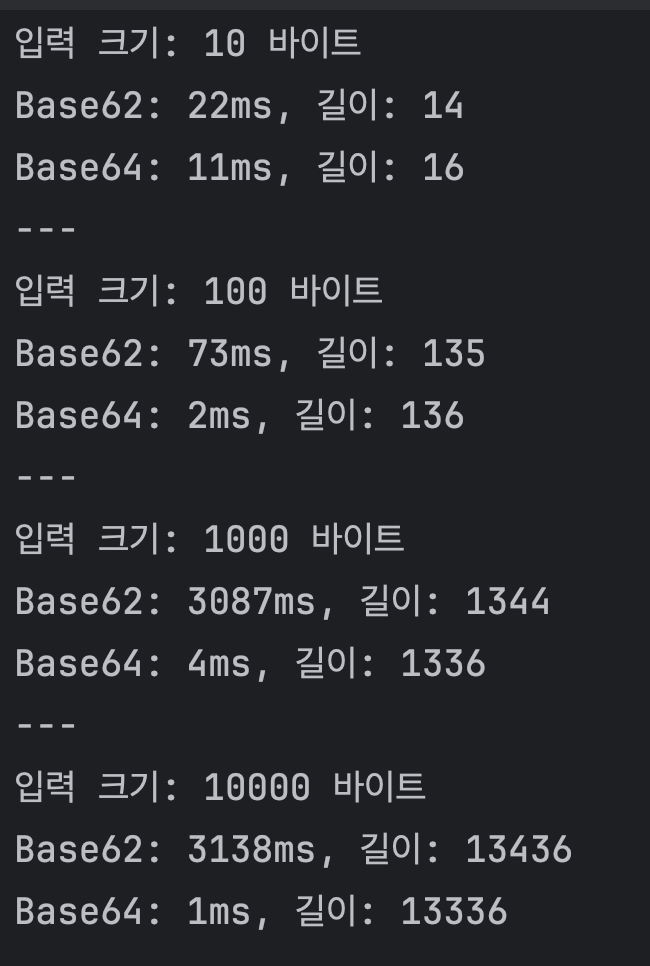
1. 성능 (시간)
- Base62: 입력 크기가 작을 때(10 바이트) 22ms가 소요되었으며, 입력 크기가 커질수록 시간이 급격히 증가했다. 1000 바이트와 10000 바이트 입력에서는 각각 3087ms와 3138ms가 소요되었다.
- Base64: 입력 크기가 작을 때(10 바이트) 11ms가 소요되었으며, 입력 크기가 커져도 성능이 크게 저하되지 않았다. 1000 바이트와 10000 바이트 입력에서는 각각 4ms와 1ms가 소요되었다.
2. 인코딩 결과 길이
- Base62
- 입력 크기 10 바이트: 인코딩 결과 길이 14
- 입력 크기 100 바이트: 인코딩 결과 길이 135
- 입력 크기 1000 바이트: 인코딩 결과 길이 1344
- 입력 크기 10000 바이트: 인코딩 결과 길이 13436
- Base64
- 입력 크기 10 바이트: 인코딩 결과 길이 16
- 입력 크기 100 바이트: 인코딩 결과 길이 136
- 입력 크기 1000 바이트: 인코딩 결과 길이 1336
- 입력 크기 10000 바이트: 인코딩 결과 길이 13336
3. 비교
- 성능
- Base64는 모든 입력 크기에서 일관되게 빠른 성능을 보였다.
- Base62는 입력 크기가 커질수록 성능이 급격히 저하되었다.
- 인코딩 결과 길이
- Base62와 Base64의 인코딩 결과 길이는 비슷하지만, Base62가 약간 더 길다.
- 입력 크기가 커질수록 Base62의 인코딩 결과 길이가 Base64보다 더 길어지는 경향이 있다.
따라서 Base62 인코딩 방식을 선택한 이유는 다음과 같다. 먼저, Base62는 URL 안전성이 뛰어나다. URL에서 안전하게 사용할 수 있는 문자만을 사용하여 추가적인 URL 인코딩 과정이 필요 없어 시스템의 복잡성을 줄이고 오류 가능성을 낮춘다. 이는 데이터 무결성 측면에서도 중요한 이점을 제공한다. 순수한 알파벳과 숫자로만 구성되어 URL 전송 과정에서 데이터가 변형될 가능성이 낮아, 주소 정보의 정확성이 중요한 약국 위치 추천 시스템에 적합하다. 또한, Base62는 패딩 문자를 사용하지 않아 일관된 길이의 출력을 제공하며, 이로 인해 패딩 처리에 대한 추가적인 로직이 필요 없어 시스템을 단순화한다.
Base62의 또 다른 장점은 오류 감지 능력이다. 모든 문자가 의미를 가지므로 잘못된 문자가 포함되면 즉시 오류를 감지할 수 있어 시스템의 안정성과 신뢰성을 높인다. 사용자 경험 측면에서도 Base62는 이점을 제공한다. URL에 직접 사용할 수 있는 인코딩 결과는 사용자 친화적인 링크 생성을 가능하게 하여, 사용자들이 주소를 공유하거나 저장할 때 더욱 편리하다.
성능 면에서 Base62는 Base64에 비해 인코딩 속도가 약간 느리고 결과 길이가 조금 더 길다는 단점이 있다. 그러나 주소 인코딩이 빈번한 작업이 아니므로 이러한 차이는 실제 시스템 운영에 큰 영향을 미치지 않는다. 오히려 데이터의 정확성과 안정성이 더 중요한 요소이며, 이 점에서 Base62가 우수하다.
장기적인 유지보수성 측면에서도 Base62는 이점을 제공한다. 추가적인 URL 인코딩이나 패딩 처리가 필요 없어 시스템의 복잡성이 감소하며, 이는 장기적으로 시스템의 유지보수를 더 쉽게 만든다.
결론적으로, Base62는 이 프로젝트의 핵심 요구사항인 데이터 정확성, URL 안전성, 시스템 안정성을 모두 만족시킨다. 약간의 성능 차이는 이러한 이점들로 충분히 상쇄되며, 장기적으로 더 안정적이고 유지보수가 용이한 시스템을 구축할 수 있게 해 준다. 따라서 Base62는 이 약국 위치 추천 시스템 프로젝트에 가장 적합한 인코딩 방식이라고 판단된다.
'BackEnd > Project' 카테고리의 다른 글
| [ParmNav] CI/CD 구축 (2) | 2024.09.26 |
|---|---|
| [PharmNav] Redis vs DB 조회 성능 비교 분석 (0) | 2024.09.24 |
| [PharmNav] Kafka vs Redis 성능 비교 분석 (1) | 2024.09.24 |
| [PharmNav] kafka를 통한 성능 향상 (0) | 2024.09.20 |
| [BigData] Ch12. Kafka추가 활용 사례 (2) | 2024.09.19 |



